


AWSのクラウドウォッチって便利ですね!
クラウドウォッチのアラームを設定することで、AWS仮想ホスト障害時のオートリカバリだけでなく、AWS仮想ゲストハング時のEC2自動再起動もクラウドウォッチを使うだけで実現できます。
レジュメ
EC2のOSがハングした時に自動再起動で復旧するためのクラウドウォッチ設定
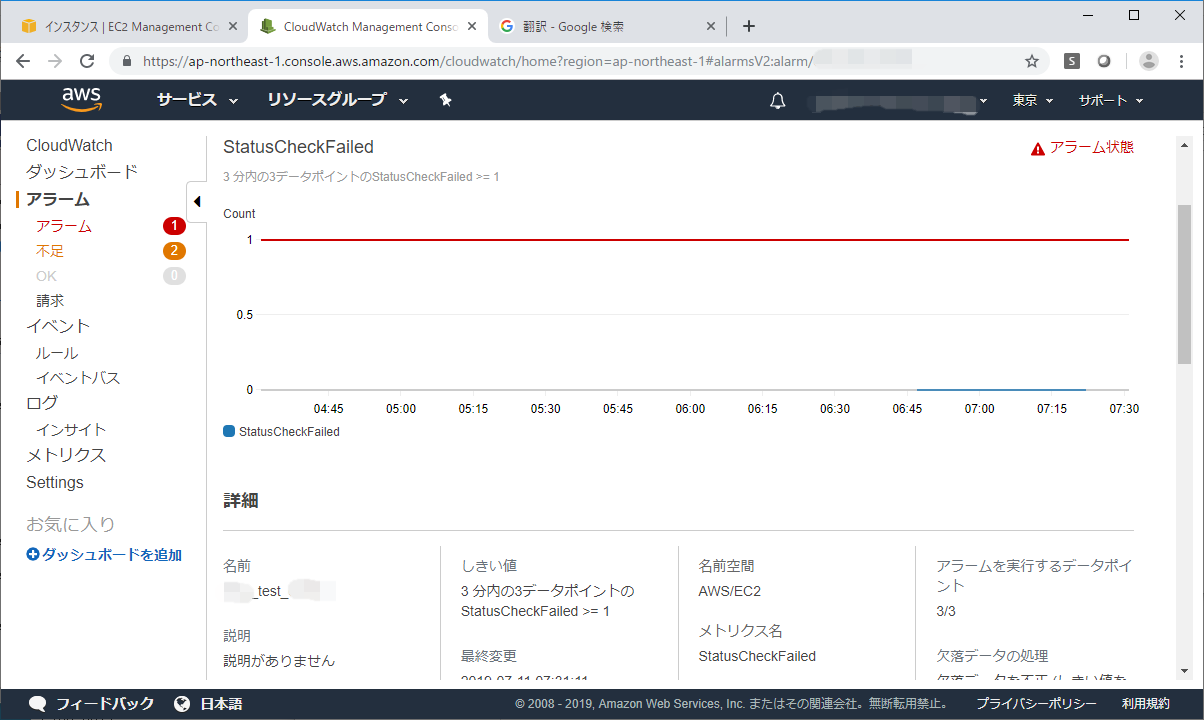
AWSのクラウドウォッチには、StatusCheckFailedといった、障害を検知するメトリクスがあります。
この StatusCheckFailedを検知してEC2の自動再起動をする設定がクラウドウォッチで可能です。
StatusCheckFailed_Systemとは?
StatusCheckFailed_Systemというメトリクスは、AWS仮想ホストでの障害を検知し、障害があると「1」となります。
StatusCheckFailed_Systemで検知するAWS設備側の障害は、
- ネットワーク接続の喪失
- システム電源の喪失
- 物理ホストのソフトウェアの問題
- 物理ホストのハードウェアの問題
です。
StatusCheckFailed_System≧1の場合、EC2を「復旧」させることをオートリカバリ呼ばれていたりします。
参考:【新機能】EC2 Cloudwatchの新機能「Auto Recovery」を使ってみた | DevelopersIO
StatusCheckFailed_Instanceとは?
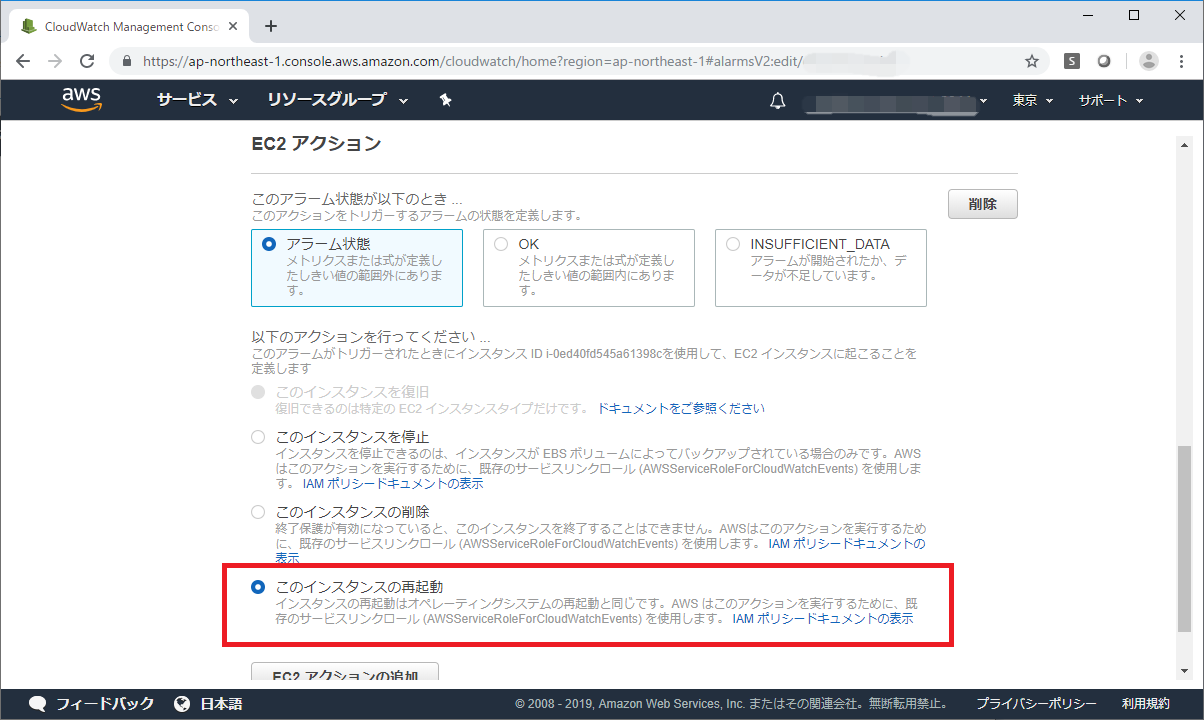
StatusCheckFailed_Instanceは、EC2のOSがハングしていたりすると、StatusCheckFailed_Instance=1となります。
StatusCheckFailed_Instance≧1を検知して、EC2を強制的にAWSコンソールから再起動させたような設定が、クラウドウォッチで可能です。
StatusCheckFailedとはStatusCheckFailed_System+StatusCheckFailed_Instance。EC2のステータスチェック
StatusCheckFailedメトリクスは、StatusCheckFailed_SystemとStatusCheckFailed_Instanceを足した値になります。
どちらかで障害があると、StatusCheckFailed=1になります。
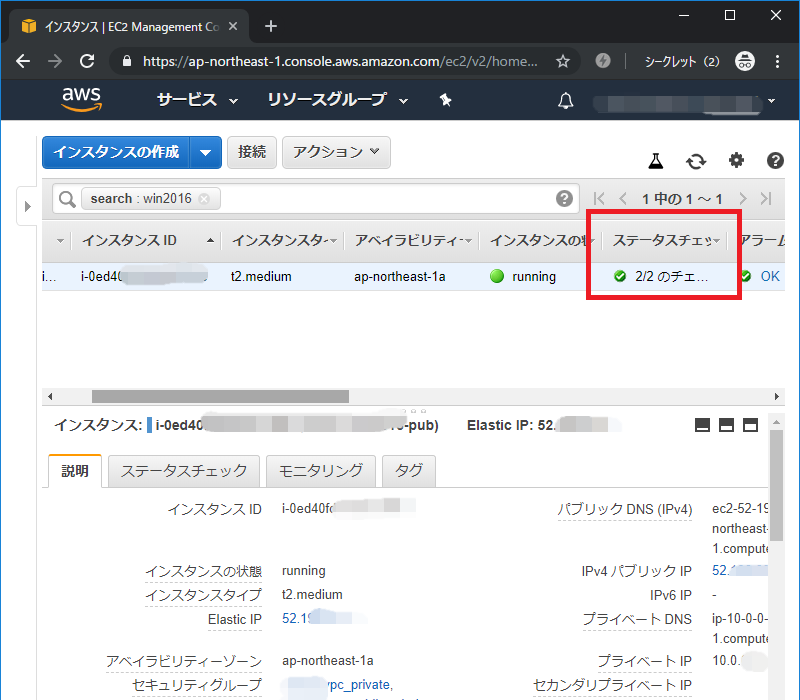
また、EC2一覧の「ステータスチェック」の「2/2」がこの StatusCheckFailed_SystemとStatusCheckFailed_Instance の2つのチェックになります。
例えば、「1/2」は StatusCheckFailed_System=0でAWSホストに障害はないが、StatusCheckFailed_Instance =1でEC2がハングしているという意味になります。
「2/2」の場合、 StatusCheckFailed_SystemもStatusCheckFailed_Instance もOK(正常)ということです。
StatusCheckFailed_Instance≧1で自動再起動設定した場合、OSシャットダウンすると自動再起動が発動するかどうか?
OSのハングはなかなか通常無いので確認するのが難しいのですが、
- EC2のOSシャットダウン時のStatusCheckFailed_Instance≧1では自動再起動は実施されれず
- EC2のOSハング時のStatusCheckFailed_Instance≧1では自動再起動は実施されます。
前者の、OSシャットダウン時はEC2が起動していないので「再起動」が実行できず以下のようなエラーがメールできます。

EC2の再起動には失敗したという内容のメールになります。
つまり、検知はし再駆動命令は投げるのですが、OSは自動起動はしなく失敗に終わるイメージになります。