

Web+DB構成のインフラを考えたときに、Webサーバ(アプリケーションサーバ)からDBへの接続にjavaのJDBCなんかでは、昔はレスポンス・パフォーマンスを少しでも良くするために接続プール(コネクションプール)を利用するのが定石でした。
最近のAWS事情も考え、複数のリードレプリカのフロントに、HAproxyを置く場合、どのようなことが考えられるか机上ではありますが情報を集めてみました。
レジュメ
環境・前提条件
一般的によくあるWeb+DB構成で、話題のターゲットはWebとDBの間の結合部分です。
- フロントのWebサーバ(アプリケーションサーバ)ではTomcatによるJavaアプリを想定
- バックエンドのDBサーバーにはAWSのRDSリードレプリカを複数(IPアドレスは変更されてしまうかもしれない)
DBのフロントにHAproxyを置く場合のメリット・デメリットを検討してみました。
HAproxyはDBフロントではレイヤ4のロードバランサでしかない

参考:HAProxy Configuration Manual
負荷分散視点でHAproxyを見た場合の話です。
HAproxyは、mysql-checkなどでMySQL DBサーバの成否確認まで出来ますが、
実際のDBへの負荷分散は
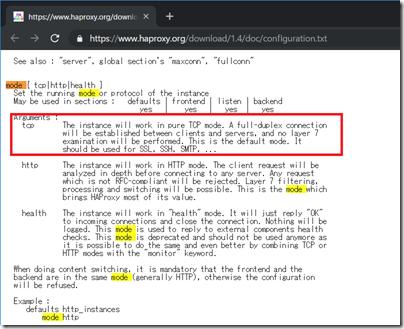
mode TCP
を使用した、レイヤ4(TCP)での負荷分散でしかないです。
そのため、接続プール(コネクションプール)を利用してしまうとHAproxyは負荷分散としては意味をなさなくなります。
負荷分散視点でのHAproxy導入の場合、接続プール(コネクションプール)を使用してはだめですね。
※ httpに対しては「mode http」というレイヤ7でのバランシングも可能です。
コネクションプーリングの接続タイミングは?JDBC挙動

参考:2.1.2.2 JDBCドライバでのコネクションプーリング
webサーバ(アプリケーションサーバー)がコネクションプーリング(接続プール)するタイミングは、
アプリプリケーション(Tomcat)の起動時ではなく、DB接続時に接続プールが無ければ新規でDB接続し、
一度、DB接続したコネクションをプールしていく(足りなければ最大数までコネクションを増やす)挙動とのことです。
導入するなら要確認ポイント:
一度に、最大数のDBコネクションを張るわけでは無いので、複数のリードレプリカクラスタを利用した場合は、接続タイミング次第では別々のRDSサーバーにDB接続プールされるかもしれませんね。
要確認。HAproxyは実はDNSキャッシュしてしまう!?

参考:HAProxyをDNS名で指定したバックエンドのIPアドレスが変わったらリロードする | cloudpack.media
こちらの情報には驚きました、、、しかしあり得なくはないです(導入するなら要確認ポイント)
通常、Linuxの場合はDNSレコードはキャッシュされず、使用するたびにDNSサーバへアクセスします。
しかし、アプリケーションによっては、処理をなるべく減らすために、初回DNS名前解決時にIPアドレスを覚えてしまうような作りをとることができます。
こういうアプリケーションの場合、可用性視点でDNSレコードを考えているとうまく可用性が取れない挙動となってしまいます、、、
DNSレコードをキャッシュするとしてもせめてレコードのTTLに則ってくれると良いのですが、こういうアプリケーションはそのようにはなってない可能性が高いです。
なるほどHAproxy+SQL